算法-图/DFS/BFS/并查集-岛屿数量
本文共 8376 字,大约阅读时间需要 27 分钟。
算法-图/DFS/BFS/并查集-岛屿数量
1 题目概述
1.1 题目出处
https://leetcode-cn.com/problems/number-of-islands
1.2 题目描述
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:
11110 11010 11000 00000 输出: 1 示例 2:输入:
11000 11000 00100 00011 输出: 3 解释: 每座岛屿只能由水平和/或竖直方向上相邻的陆地连接而成。2 图-DFS
2.1 思路
将岛屿分布看做有向图,深度遍历该节点的上下左右四个方向。
遍历到一个为’1’的节点时,标记为’0’代表已经遍历过下次不再遍历。
2.2 代码
class Solution { public int numIslands(char[][] grid) { int result = 0; if(grid == null || grid.length == 0){ return result; } for(int i = 0; i < grid.length; i++){ char[] columns = grid[i]; for(int j = 0; j < columns.length; j++){ char c = columns[j]; if(c == '1'){ dfs(grid, i, j); result++; } } } return result; } private void dfs(char[][] grid, int row, int column){ char[] columns = grid[row]; char c = columns[column]; if(c == '0'){ return; }else{ // 标记为'0'代表已经遍历过下次不再遍历。 grid[row][column] = '0'; // 继续遍历上下左右四个相邻位置 if(column - 1 > -1){ dfs(grid, row, column - 1); } if(column + 1 < columns.length){ dfs(grid, row, column + 1); } if(row + 1 < grid.length){ dfs(grid, row + 1, column); } if(row - 1 > -1){ dfs(grid, row - 1, column); } } }} 2.3 时间复杂度
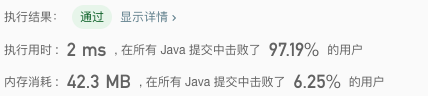
- 其中 N 和 M 分别为行数和列数。
2.4 空间复杂度
O(N*M)
- 因为需要递归
3 BFS
3.1 思路
将岛屿分布看做有向图,遍历开始后,从当前节点广度优先遍历。
3.2 代码
class Solution { private Set recordSet = new HashSet<>(); public int numIslands(char[][] grid) { int result = 0; if(grid == null || grid.length == 0){ return result; } for(int i = 0; i < grid.length; i++){ char[] columns = grid[i]; for(int j = 0; j < columns.length; j++){ char c = columns[j]; if(c == '1'){ bfs(grid, i, j); result++; } } } return result; } private void bfs(char[][] grid, int row, int column){ char[] columns = grid[row]; char c = columns[column]; if(c == '0'){ return; } LinkedList coordinateQueue = new LinkedList<>(); coordinateQueue.add(new int[]{ row, column}); // bfs while(!coordinateQueue.isEmpty()){ int[] coordinate = coordinateQueue.poll(); int i = coordinate[0]; int j = coordinate[1]; if(grid[i][j] == '0'){ continue; } grid[i][j] = '0'; if(j - 1 > -1){ coordinateQueue.add(new int[]{ i, j - 1}); } if(j + 1 < columns.length){ coordinateQueue.add(new int[]{ i, j + 1}); } if(i + 1 < grid.length){ coordinateQueue.add(new int[]{ i + 1, j}); } if(i - 1 > -1){ coordinateQueue.add(new int[]{ i - 1, j}); } } }} 3.3 时间复杂度

- 其中 N 和 M 分别为行数和列数。
3.4 空间复杂度
O(min(M,N))
- 最坏情况全是岛屿
4 效率很低的第一版并查集
4.1 思路
做并查集,遇到相邻的’1’节点就合并成一个并查集。
最后返回不同的并查集数。
4.2 代码
class Solution { public int numIslands(char[][] grid) { int result = 0; if(grid == null || grid.length == 0){ return result; } int[] unionFindSet = new int[grid.length * grid[0].length]; for(int i = 0; i < grid.length; i++){ char[] columns = grid[i]; for(int j = 0; j < columns.length; j++){ char c = columns[j]; if(c == '1'){ // 初始化岛节点的并查集为index+1 find(unionFindSet, i * columns.length + j); // 连接右侧节点 if(j + 1 < columns.length && grid[i][j + 1] == '1'){ // 这里需要将二维数组转为一位数组的下标 // 所以使用 当前行*列总数得到该行在一位数组中的首个下标, // 再加上当前列作为偏移数得到在一维数组的下标 union(unionFindSet, i * columns.length + j, i * columns.length + j + 1); } // 连接下侧节点 if(i + 1 < grid.length && grid[i+1][j] == '1'){ union(unionFindSet, i * columns.length + j, (i + 1) * columns.length + j); } } } } Set filter = new HashSet<>(); for(int i : unionFindSet){ if(i != 0){ filter.add(i); } } return filter.size(); } private void union(int[] unionFindSet, int p, int q){ int left = find(unionFindSet, p); int right = find(unionFindSet, q); if(left == right){ return; } // 查找出所有和右边元素同一个并查集元素,和左边合并 for(int i = 0; i < unionFindSet.length; i++){ if(unionFindSet[i] == right){ unionFindSet[i] = left; } } } private int find(int[] unionFindSet, int p){ if(unionFindSet[p] == 0){ unionFindSet[p] = p + 1; } return unionFindSet[p]; }} 4.3 时间复杂度

5 并查集-优化
5.1 思路
合并两个不同祖先的节点时,将他们的祖先合并为一个即可。
最后遍历计算出不同的祖先数作为结果返回。
在union的时候还采用了压缩路径优化方法,提升查找效率。
5.2 代码
class Solution { public int numIslands(char[][] grid) { int result = 0; if(grid == null || grid.length == 0){ return result; } int[] unionFindSet = new int[grid.length * grid[0].length]; // 初始化所有节点的并查集,父节点设为自己 for(int i = 0; i < grid.length; i++){ char[] columns = grid[i]; for(int j = 0; j < columns.length; j++){ unionFindSet[i * columns.length + j] = i * columns.length + j; } } // 下面开始合并岛节点 for(int i = 0; i < grid.length; i++){ char[] columns = grid[i]; for(int j = 0; j < columns.length; j++){ char c = columns[j]; if(c == '1'){ // 初始化岛节点的并查集为index+1 // find(unionFindSet, i * columns.length + j); // 连接右侧节点 if(j + 1 < columns.length && grid[i][j + 1] == '1'){ // 这里需要将二维数组转为一位数组的下标 // 所以使用 当前行*列总数得到该行在一位数组中的首个下标, // 再加上当前列作为偏移数得到在一维数组的下标 union(unionFindSet, i * columns.length + j, i * columns.length + j + 1); } // 连接下侧节点 if(i + 1 < grid.length && grid[i+1][j] == '1'){ union(unionFindSet, i * columns.length + j, (i + 1) * columns.length + j); } }else{ // 海洋节点,将他们的父节点设为-1,不参与累计 unionFindSet[i * columns.length + j] = -1; } } } // 去重根节点 Set filter = new HashSet<>(); // 将所有父节点不为-1的节点全部取出,并寻找他们的父节点 // 只要父节点不为-1就放入过滤器统计 for(int i = 0; i < unionFindSet.length; i++){ if(unionFindSet[i] == -1){ continue; } int root = find(unionFindSet, i); if(root > -1){ filter.add(root); } } // 最终返回不重复的根节点数 return filter.size(); } private void union(int[] unionFindSet, int p, int q){ int left = find(unionFindSet, p); int right = find(unionFindSet, q); // 说明本来就在一个并查集内,不用处理 if(left == right){ return; } // 将右边元素的老祖先作为左边元素老祖先的父节点,实现联通 unionFindSet[left] = right; } private int find(int[] unionFindSet, int p){ int son = p; // 寻找祖先根节点 while(p != unionFindSet[p]){ p = unionFindSet[p]; } // 路径压缩优化,将当前节点及祖先节点的父节点都设为祖先根节点 // 即将高度压缩为2,方便查找 while(son != p){ int tmp = unionFindSet[son]; unionFindSet[son] = p; son = tmp; } return p; } } 5.3 时间复杂度

5.4 空间复杂度
O(M*N)
参考文档
转载地址:http://fmpkb.baihongyu.com/
你可能感兴趣的文章
C++/C 宏定义(define)中# ## 的含义 宏拼接
查看>>
Git安装配置
查看>>
linux中fork()函数详解
查看>>
C语言字符、字符串操作偏僻函数总结
查看>>
Git的Patch功能
查看>>
分析C语言的声明
查看>>
TCP为什么是三次握手,为什么不是两次或者四次 && TCP四次挥手
查看>>
C结构体、C++结构体、C++类的区别
查看>>
进程和线程的概念、区别和联系
查看>>
CMake 入门实战
查看>>
绑定CPU逻辑核心的利器——taskset
查看>>
Linux下perf性能测试火焰图只显示函数地址不显示函数名的问题
查看>>
c结构体、c++结构体和c++类的区别以及错误纠正
查看>>
Linux下查看根目录各文件内存占用情况
查看>>
A星算法详解(个人认为最详细,最通俗易懂的一个版本)
查看>>
利用栈实现DFS
查看>>
逆序对的数量(递归+归并思想)
查看>>
数的范围(二分查找上下界)
查看>>
算法导论阅读顺序
查看>>
Windows程序设计:直线绘制
查看>>